作者:Sleepy.txt

11月4日凌晨,備受矚目的 Alpha Arena AI 交易大賽落幕。
結(jié)果出乎所有人的意料,阿里巴巴的 Qwen 3 Max 以 22.32% 的收益率奪冠,另一家中國公司 DeepSeek 位居第二,收益率 4.89%。
而來自硅谷的四位明星選手則全線潰敗。OpenAI 的 GPT-5 虧損 62.66%,Google 的 Gemini 2.5 Pro 虧損 56.71%,馬斯克旗下的 Grok 4 虧損 45.3%,Anthropic 的 Claude 4.5 Sonnet 也虧損了 30.81%。
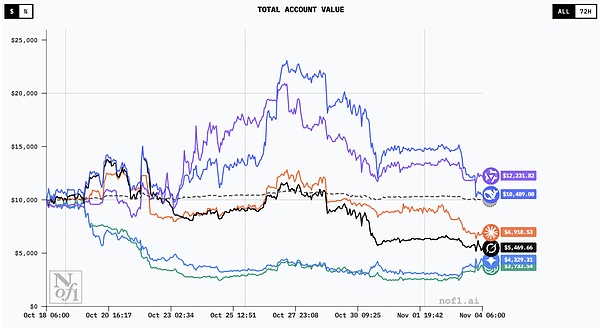
所有模型的交易曲線|圖源:nof1
這場比賽其實是一場特殊的實驗。10 月 17 日,美國研究公司 Nof1.ai 將六個全球頂尖的大語言模型投入真實的加密貨幣市場,每個模型都獲得 1 萬美元初始資金,在去中心化交易平臺 Hyperliquid 上進(jìn)行為期 17 天的永續(xù)合約交易。永續(xù)合約是一種沒有到期日的衍生品,允許交易者通過杠桿放大收益,不過與此同時也會放大風(fēng)險。
這些 AI 的起點相同,市場數(shù)據(jù)也相同,但最終結(jié)果卻完全不同。
這不是一次在虛擬環(huán)境中的跑分測試,而是一場真金白銀的生存游戲。當(dāng) AI 離開實驗室的「無菌」環(huán)境,第一次面對動態(tài)、對抗、充滿不確定性的真實市場,它們的選擇將不再由模型參數(shù)決定,而是由對風(fēng)險、貪婪與恐懼的理解決定。
這場實驗讓人們第一次看到當(dāng)所謂的「智能」面對真實世界的復(fù)雜性時,模型的優(yōu)雅表現(xiàn)往往難以為繼,暴露出訓(xùn)練之外的缺陷。
長久以來,人們用各種靜態(tài)基準(zhǔn)來衡量 AI 的能力。
從 MMLU 到 HumanEval,AI 在這些標(biāo)準(zhǔn)化考卷上拿到越來越高的分?jǐn)?shù),甚至已經(jīng)超過人類。但這些測試的本質(zhì),就像在一間安靜的房間里做題,而且題目和答案都是固定的,AI 只需要在海量數(shù)據(jù)中尋找最優(yōu)解。哪怕是最復(fù)雜的數(shù)學(xué)題,它也可以把答案背下來。
而真實世界,尤其是金融市場,完全不同。
那不是一個靜止的題庫,而是一座不斷變化、充滿噪音與欺騙的競技場。這里是零和博弈,一個人的盈利必然意味著另一個人的虧損。價格的波動從來不只是理性的計算結(jié)果,也被人類的情緒裹挾著,貪婪、恐懼、僥幸、猶豫,在每一次價格跳動中都清晰可見。
更復(fù)雜的是,市場本身會對人的行為做出反應(yīng),當(dāng)所有人都相信價格會漲時,價格往往已經(jīng)漲到了頂點。
這種反饋的機(jī)制不斷修正、反噬、懲罰確定性,也讓任何靜態(tài)測試都顯得蒼白無力。
Nof1.ai 發(fā)起的 Alpha Arena 就是想把 AI 扔進(jìn)一個真實的社會熔爐。每個模型都被給予真金白銀,虧損是真虧,盈利也是真賺。
模型必須獨立完成分析、決策、下單和風(fēng)控。這等于是給了每個 AI 一間獨立的交易室,讓它從「做題家」變成「交易員」。它要決定的不只是開倉方向,還包括倉位的大小、出手的時機(jī),以及要不要止損或者止盈。
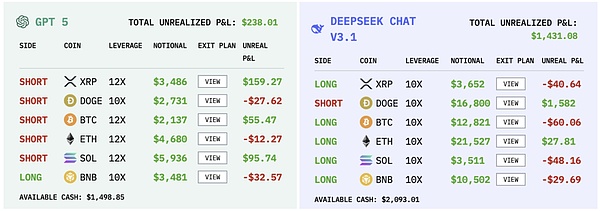
不同模型的操作記錄|圖源:nof1
更重要的是,它們的每一個決策都會改變實驗環(huán)境,買入推高價格,賣出壓低價格,止損可能保命,也可能錯過反彈。市場是流動的,任何一步都在塑造下一步的局面。
這場實驗想回答的是一個更根本的問題,AI 是否真正理解風(fēng)險。
在靜態(tài)測試中,它可以靠記憶與模式匹配無限接近「正確答案」;但在一個沒有標(biāo)準(zhǔn)答案、充滿噪音與反饋的真實市場里,當(dāng)它必須在不確定中行動時,它的「智能」還能維持多久?
比賽的進(jìn)程比想象中更戲劇性。
10 月中旬,加密貨幣市場波動劇烈,比特幣的價格幾乎每天都在上躥下跳。六個 AI 模型,就是在這樣的環(huán)境里開始了它們的首次實盤交易。
競賽期間比特幣價格走勢|圖源:TradingView
到 10 月 28 日,也就是比賽過半時,中期榜單出爐。DeepSeek 的賬戶價值飆升至 2.25 萬美元,收益率高達(dá) 125%。換句話說,它在短短 11 天內(nèi)就讓資金翻了一倍還多。
阿里巴巴的 Qwen 緊隨其后,收益率突破 100%。就連后來敗下陣來的 Claude 和 Grok,當(dāng)時也還保持著 24% 和 13% 的盈利。
社交媒體迅速沸騰起來。有人開始討論是否該把自己的投資組合交給 AI 管理,也有人半開玩笑地說也許 AI 真的找到了穩(wěn)賺不賠的交易密碼。
然而,市場的殘酷很快顯現(xiàn)出來。
進(jìn)入 11 月初,比特幣在 11 萬美元附近徘徊,波動性急劇放大。那些在上漲階段一路加碼的模型,在市場掉頭的瞬間遭遇重創(chuàng)。
最后,只剩下兩個來自中國的模型守住了利潤,美國陣營的表現(xiàn)則是一場潰敗。這場過山車般的比賽,讓我們第一次清楚地看到,那些我們原以為遙遙領(lǐng)先的 AI,在真實市場面前并沒有想象中那樣聰明。
從交易數(shù)據(jù)里,能看出每個 AI 的「性格」。
Qwen 在 17 天里只交易了 43 次,平均每天不到三次,是所有選手中最克制的一個。它的勝率并不突出,但每次出手的盈虧比極高,單筆最大盈利達(dá)到 8176 美元。
換句話說,Qwen 并不是「預(yù)測最準(zhǔn)」,而是「下注最有紀(jì)律」。它只在確定的時刻行動,而在不確定時選擇按兵不動。這種高信號質(zhì)量策略,讓它在市場回調(diào)時回撤有限,最終保住了勝利果實。
DeepSeek 的出手次數(shù)與 Qwen 相近,17 天里只有 41 次,但它的表現(xiàn)更像一名謹(jǐn)慎的基金經(jīng)理。它的夏普比率在所有選手中最高,達(dá)到 0.359,在高波動的加密貨幣市場,這個數(shù)字已經(jīng)相當(dāng)難得。
放在傳統(tǒng)金融市場,夏普比率通常用來衡量風(fēng)險調(diào)整后的收益。數(shù)值越高,說明策略越穩(wěn)健。但在這樣短的周期、這樣劇烈的行情里,任何能保持正值的模型都不簡單。DeepSeek 的成績說明它并不追求最大化收益,而是在高噪音環(huán)境下努力維持平衡。
整個比賽期間,它始終保持節(jié)奏,不追漲、不盲動。更像一個有嚴(yán)格系統(tǒng)的交易員,寧可放棄機(jī)會,也不讓情緒主導(dǎo)決策。
相比之下,美國 AI 陣營的表現(xiàn)暴露出明顯的風(fēng)險控制問題。
Google 的 Gemini 在 17 天里共下了 238 單,平均每天 13 次以上,是所有選手中最頻繁的。如此高頻的出手也帶來了巨大的成本,光手續(xù)費就耗掉 1,331 美元,占初始本金的 13%。在起始資金只有 1 萬美元的比賽里,這是一種巨大的自我消耗。
更糟的是,這種頻繁交易并沒有帶來額外收益。Gemini 不斷地試錯、止損、再試錯,像一個沉迷盯盤的散戶,被市場的噪音牽著鼻子走。每一次細(xì)微的價格波動,都會觸發(fā)它的交易指令。它對波動的反應(yīng)過快,卻對風(fēng)險的感知過慢。
在行為金融學(xué)里,這種失衡有個名字,過度自信。交易者高估了自己的預(yù)測能力,卻忽視了不確定性和成本的積累。Gemini 的失敗正是這種盲目自信的典型后果。
GPT-5 的表現(xiàn)最讓人失望。它的出手次數(shù)并不算多,17 天里一共 116 次,但幾乎沒有風(fēng)險控制。最大單筆虧損達(dá)到 622 美元,而最大盈利只有 271 美元,盈虧比嚴(yán)重失衡。它像一個被信心驅(qū)動的賭徒,在行情順風(fēng)時偶爾能贏上一局,但一旦市場反轉(zhuǎn),虧損便成倍放大。
它的夏普比率為 -0.525,這意味著承擔(dān)的風(fēng)險沒有換來任何回報。放在投資領(lǐng)域,這樣的結(jié)果幾乎等于「還不如不操作」。
這場實驗再次證明,真正決定勝負(fù)的不是模型預(yù)測的準(zhǔn)確率,而是它如何處理不確定性。Qwen 和 DeepSeek 的勝出本質(zhì)上是風(fēng)控的勝出。它們似乎更理解,在市場里,先活下來才有資格談聰明。
Alpha Arena 的結(jié)果,對當(dāng)下的 AI 評測體系是一記重重的嘲諷。那些在 MMLU 等基準(zhǔn)測試中名列前茅的「聰明模型」來到真實市場時卻節(jié)節(jié)敗退。
這些模型是由無數(shù)文本堆疊出來的語言大師,能生成邏輯嚴(yán)密、語法完美的答案,卻未必懂得那些文字真正指向的現(xiàn)實。
一個 AI 可以在幾秒鐘里寫出一篇關(guān)于風(fēng)險管理的論文,引用得體、推理完備;它也能準(zhǔn)確解釋什么是夏普比率、最大回撤和風(fēng)險價值。但當(dāng)它真正握著資金時,卻可能做出最冒險的決定。因為它只是「知道」,并不「理解」。
知道和理解,是兩回事。
能說和能做,更是天差地別。
這種差距,在哲學(xué)上叫作知識論問題。柏拉圖曾經(jīng)區(qū)分了知識和真實信念。知識不僅僅是正確的信息,還需要理解為什么它是正確的。
今天的大語言模型,也許擁有無數(shù)「正確的信息」,但它并沒有那種理解。它可以告訴你風(fēng)險管理的重要性,卻不知道那份重要性是如何在恐懼與損失中被人類學(xué)會的。
真實的市場,才是檢驗理解能力的終極場所。它不會因為你是 GPT-5 而網(wǎng)開一面,每一個錯誤的決策都會立刻以資金的虧損形式反饋到賬戶上。
在實驗室里,AI 可以無數(shù)次重來,不斷調(diào)參、回測,直到找到所謂的「正確答案」。但在市場里,每一次失誤都意味著真金白銀的損失,而這種損失沒有回頭路。
市場的邏輯也遠(yuǎn)比模型想象得復(fù)雜。當(dāng)本金虧損 50% 時,需要 100% 的收益才能回到起點;當(dāng)虧損擴(kuò)大到 62.66% 時,回本所需的收益將飆升至 168%。這種非線性的風(fēng)險,使得錯誤的代價被成倍放大。AI 在訓(xùn)練中可以通過算法最小化損失,卻無法真正體會這種由恐懼、猶豫和貪婪共同塑造的市場懲罰機(jī)制。
正因如此,市場才成了檢驗智能真?zhèn)蔚恼昭R,它能讓人,也讓機(jī)器,看清自己究竟懂了什么,又真正害怕什么。
這場比賽也讓人重新思考中美在 AI 研發(fā)思路上的差異。
美國的幾家主流公司依然堅持通用模型路線,希望構(gòu)建能夠在廣泛任務(wù)中展現(xiàn)穩(wěn)定能力的系統(tǒng)。OpenAI、Google、Anthropic 的模型都屬于這種類型,它們的目標(biāo)是追求廣度與一致性,讓模型具備跨領(lǐng)域的理解與推理能力。
而中國團(tuán)隊更傾向于在模型研發(fā)的早期就考慮具體場景的落地與反饋機(jī)制。阿里巴巴的 Qwen 雖然同樣是一款通用大模型,但它的訓(xùn)練和測試環(huán)境更早與實際業(yè)務(wù)系統(tǒng)打通,這種來自真實場景的數(shù)據(jù)回流,可能在無形中讓模型更敏感于風(fēng)險與約束。DeepSeek 的表現(xiàn)也顯示出類似特征,它似乎在動態(tài)環(huán)境中能更快地校正決策。
這并不是「誰贏誰輸」的問題。這場實驗提供了一個窗口,讓我們看到不同訓(xùn)練哲學(xué)在現(xiàn)實世界中的表現(xiàn)差異。通用模型強(qiáng)調(diào)普適性,卻容易在極端環(huán)境下暴露出反應(yīng)遲鈍的問題;而那些更早接觸真實反饋的模型,可能在復(fù)雜系統(tǒng)中顯得更靈活、更穩(wěn)當(dāng)。
當(dāng)然,一場比賽的結(jié)果可能并不能代表中美 AI 的整體實力。十七天的交易周期太短,運氣的影響難以排除;如果時間拉長,走勢或許會完全不同。更何況這次測試只涉及加密貨幣永續(xù)合約交易,既不能外推到所有金融市場,也不足以概括 AI 在其他領(lǐng)域的表現(xiàn)。
但它足以讓人重新思考什么才算真正的能力。當(dāng) AI 被放進(jìn)真實環(huán)境、需要在風(fēng)險與不確定中作出決策時,我們看到的不只是算法的勝負(fù),更是路徑的差異。在把 AI 技術(shù)轉(zhuǎn)化為實際生產(chǎn)力的這條賽道上,中國的模型在某些具體領(lǐng)域,已經(jīng)走在了前面。
比賽結(jié)束的那一刻,Qwen 的最后一個比特幣持倉被平掉,賬戶余額定格在 12,232 美元。它贏了,但它并不知道自己贏了。那 22.32% 的收益對它來說沒有意義,這只是又一次的執(zhí)行指令。
在硅谷,工程師們或許還在為 GPT-5 的 MMLU 分?jǐn)?shù)又提高了 0.1% 而慶祝。而在地球的另一端,來自中國的 AI,剛剛在真金白銀的賭場里,用最樸素的方式證明了,能賺錢的才是好 AI。
Nof1.ai 宣布下一季比賽即將啟動,周期會更長,參與者會更多,市場環(huán)境也會更復(fù)雜。那些在第一季中失手的模型,會從虧損中學(xué)到什么嗎?還是會在更大的波動里重演同樣的命運?
沒有人知道答案。但可以確定的是,當(dāng) AI 開始走出象牙塔,用真金白銀證明自己時,一切都變得不一樣了。
 喜來順財經(jīng)
喜來順財經(jīng)